
Forschungsdatenlebenszyklus
Das Forschungsdatenmanagement – das heißt der Umgang mit Forschungsdaten von der Entstehung bis zur Speicherung und Nachnutzung – lässt sich anschaulich als Forschungsdatenzyklus darstellen.
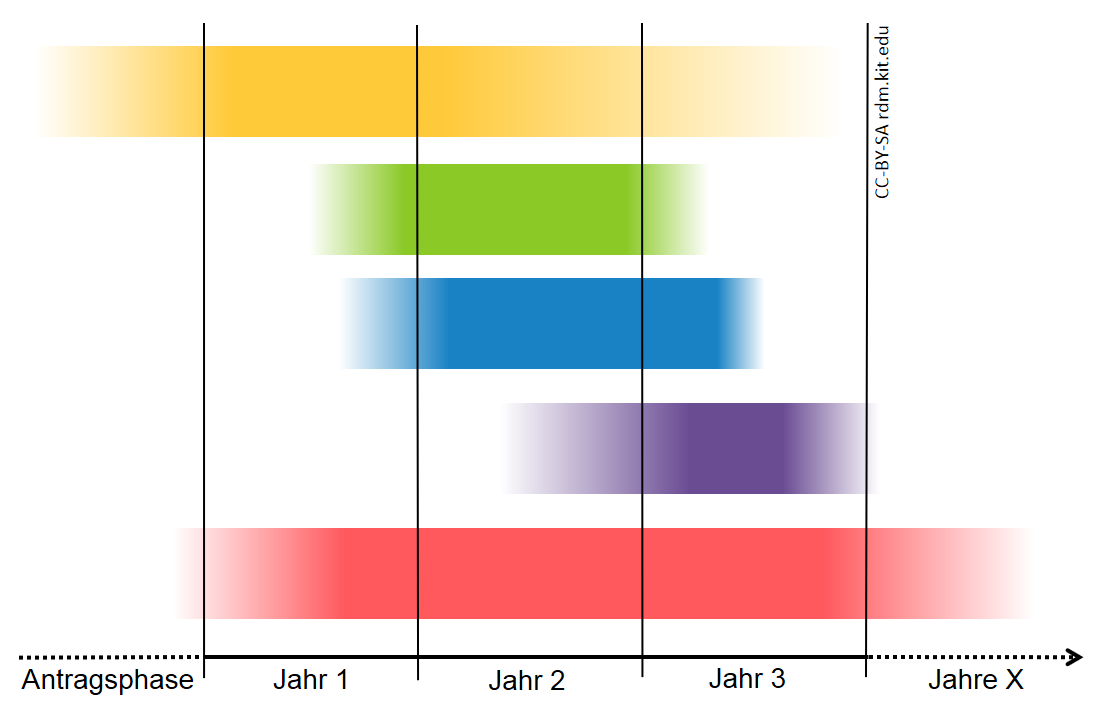
Allerdings laufen die einzelnen Phasen des Forschungsdatenmanagements im Allgemeinen nicht so sequenziell ab, wie im Forschungsdatenzyklus dargestellt. Die beispielhafte Darstellung eines Projektes in einem Gantt-Diagramm zeigt die teilweise auftretende Überlappung der Phasen.
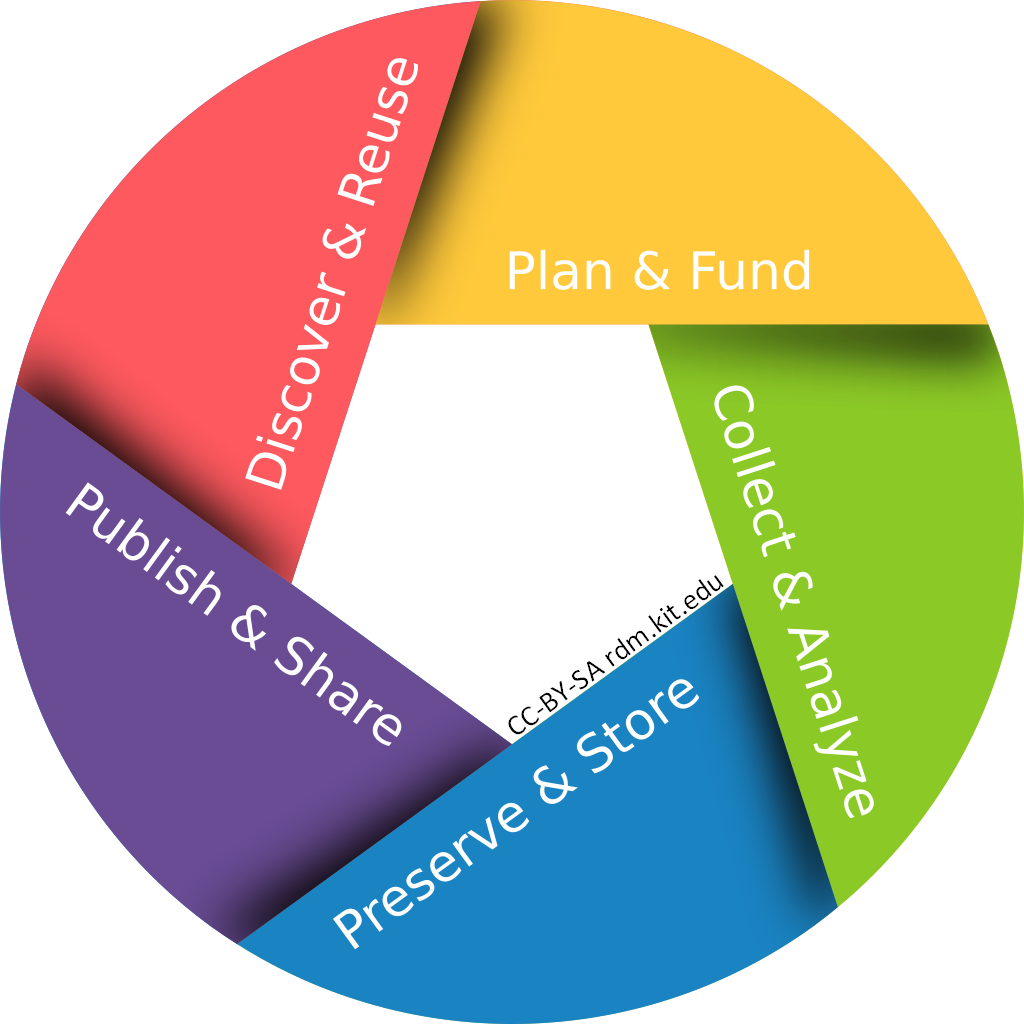
 Plan & Fund: Das Forschungsdatenmanagement beginnt mit der systematischen Planung: Welche Daten werden benötigt, erhoben, verarbeitet und gespeichert? Projektförderer verlangen in der Regel bereits bei der Antragstellung ein strukturiertes Datenmanagement. Gleichzeitig können damit auch Mittel für das Forschungsdatenmanagement beantragt werden. Hierzu haben sich im Forschungsdatenmanagement sogenannte Datenmanagementpläne (DMPs) etabliert. Tools wie RDMO und das DMPTool unterstützen die Erstellung von DMPs für Förderer und Projektleitung.
Plan & Fund: Das Forschungsdatenmanagement beginnt mit der systematischen Planung: Welche Daten werden benötigt, erhoben, verarbeitet und gespeichert? Projektförderer verlangen in der Regel bereits bei der Antragstellung ein strukturiertes Datenmanagement. Gleichzeitig können damit auch Mittel für das Forschungsdatenmanagement beantragt werden. Hierzu haben sich im Forschungsdatenmanagement sogenannte Datenmanagementpläne (DMPs) etabliert. Tools wie RDMO und das DMPTool unterstützen die Erstellung von DMPs für Förderer und Projektleitung.
 Collect & Analyse: Die Erzeugung und Erfassung der Daten, z. B. mit Sensoren oder Simulationen auf Hochleistungsrechnern, liegt im Wesentlichen in der Verantwortung der Forschenden, ebenso die Auswertung, z. B. durch Algorithmen & Software. In diesem Prozess gilt es auch die notwendigen Metadaten zur Beschreibung der Forschungsdaten mitzuerfassen, dies umfasst wissenschaftliche, administrative, sowie informationstechnische Metadaten. Ein Werkzeug, welches Forschende bei der Erfassung und Analyse unterstützt, ist das elektronische Laborbuch (ELN).
Collect & Analyse: Die Erzeugung und Erfassung der Daten, z. B. mit Sensoren oder Simulationen auf Hochleistungsrechnern, liegt im Wesentlichen in der Verantwortung der Forschenden, ebenso die Auswertung, z. B. durch Algorithmen & Software. In diesem Prozess gilt es auch die notwendigen Metadaten zur Beschreibung der Forschungsdaten mitzuerfassen, dies umfasst wissenschaftliche, administrative, sowie informationstechnische Metadaten. Ein Werkzeug, welches Forschende bei der Erfassung und Analyse unterstützt, ist das elektronische Laborbuch (ELN).
 Preserve & Store: Forschungsdaten sollten in einem geeigneten Repositorium gespeichert werden, idealerweise in fachspezifischen oder institutionellen Repositorien. Die Forschungsdaten sollten möglichst gemeinsam mit einer guten Dokumentation aufbewahrt werden, um eine Nachnutzung, insbesondere für Dritte, zu ermöglichen. Ein wichtiges Kriterium für die Speicherinfrastruktur ist die Möglichkeit der Langzeitarchivierung, z. B. über Bandspeicher.
Preserve & Store: Forschungsdaten sollten in einem geeigneten Repositorium gespeichert werden, idealerweise in fachspezifischen oder institutionellen Repositorien. Die Forschungsdaten sollten möglichst gemeinsam mit einer guten Dokumentation aufbewahrt werden, um eine Nachnutzung, insbesondere für Dritte, zu ermöglichen. Ein wichtiges Kriterium für die Speicherinfrastruktur ist die Möglichkeit der Langzeitarchivierung, z. B. über Bandspeicher.
 Publish & Share: Für die Weiterverwendung der Daten sind Zugangsbedingungen zu definieren, d. h. Zugriffs- und Nutzungsrechte, die auch die Vergabe von Patenten und Lizenzen beinhalten können. Um die erzeugten Dateien eindeutig zu identifizieren und zu referenzieren, ist die Vergabe von Persistent Identifiern (PIDs) sinnvoll. Für eine möglichst breite Verbreitung sollten bestehende Netzwerke und Fachcommunities über eine bereits bestehende und ggf. zertifizierte Infrastruktur eingebunden werden.
Publish & Share: Für die Weiterverwendung der Daten sind Zugangsbedingungen zu definieren, d. h. Zugriffs- und Nutzungsrechte, die auch die Vergabe von Patenten und Lizenzen beinhalten können. Um die erzeugten Dateien eindeutig zu identifizieren und zu referenzieren, ist die Vergabe von Persistent Identifiern (PIDs) sinnvoll. Für eine möglichst breite Verbreitung sollten bestehende Netzwerke und Fachcommunities über eine bereits bestehende und ggf. zertifizierte Infrastruktur eingebunden werden.
 Discover & Reuse: Ein gutes Forschungsdatenmanagement ermöglicht die Recherche und Nachnutzung der Ergebnisse durch andere Forschende. Diese müssen die Daten nicht erneut aufwändig erzeugen, sondern können auf den aktuellen Wissensstand aufbauen. Zum Auffinden von Daten stehen sowohl einzelne Repositorien, als auch zusammenführende Dienste wie re3data oder DataCite zur Verfügung. Auch hier müssen Forschende den rechtlichen Rahmens und die gute wissenschaftliche Praxis beachten.
Discover & Reuse: Ein gutes Forschungsdatenmanagement ermöglicht die Recherche und Nachnutzung der Ergebnisse durch andere Forschende. Diese müssen die Daten nicht erneut aufwändig erzeugen, sondern können auf den aktuellen Wissensstand aufbauen. Zum Auffinden von Daten stehen sowohl einzelne Repositorien, als auch zusammenführende Dienste wie re3data oder DataCite zur Verfügung. Auch hier müssen Forschende den rechtlichen Rahmens und die gute wissenschaftliche Praxis beachten.