
Research Data Life Cycle
Research data management - that is, the handling of research data from its creation to its storage and subsequent use - can be vividly depicted as a research data cycle.
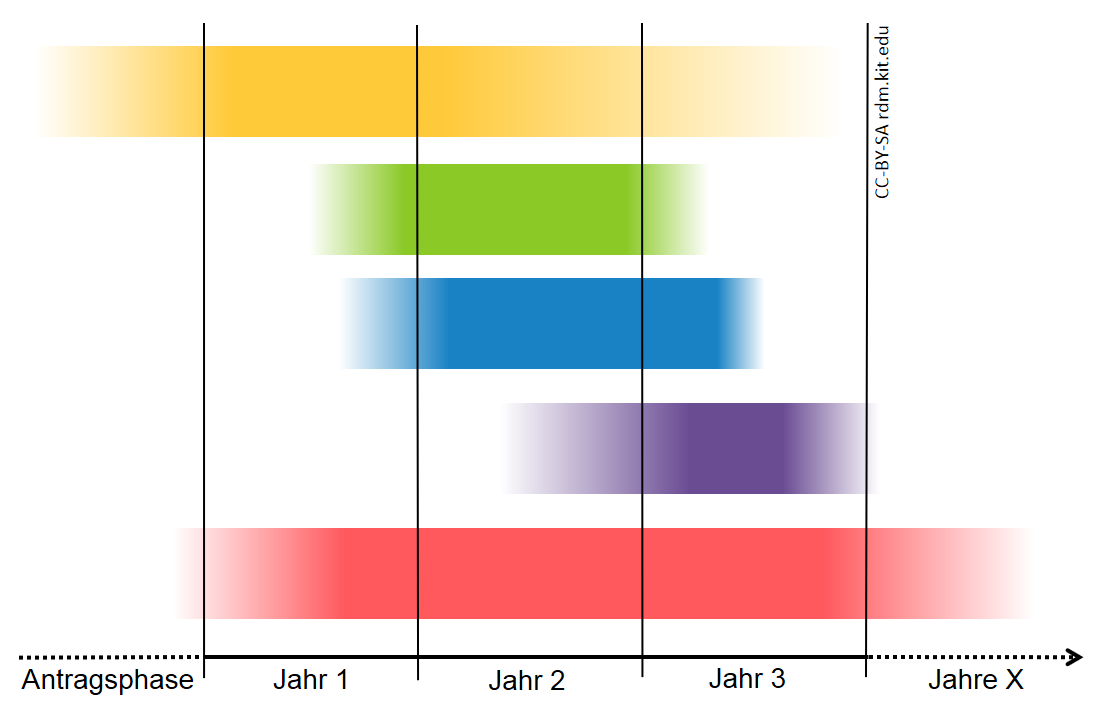
However, the individual phases of research data management generally do not proceed as sequentially as depicted in the research data cycle. The exemplary representation of a project in a Gantt chart shows the partial overlapping of the phases.
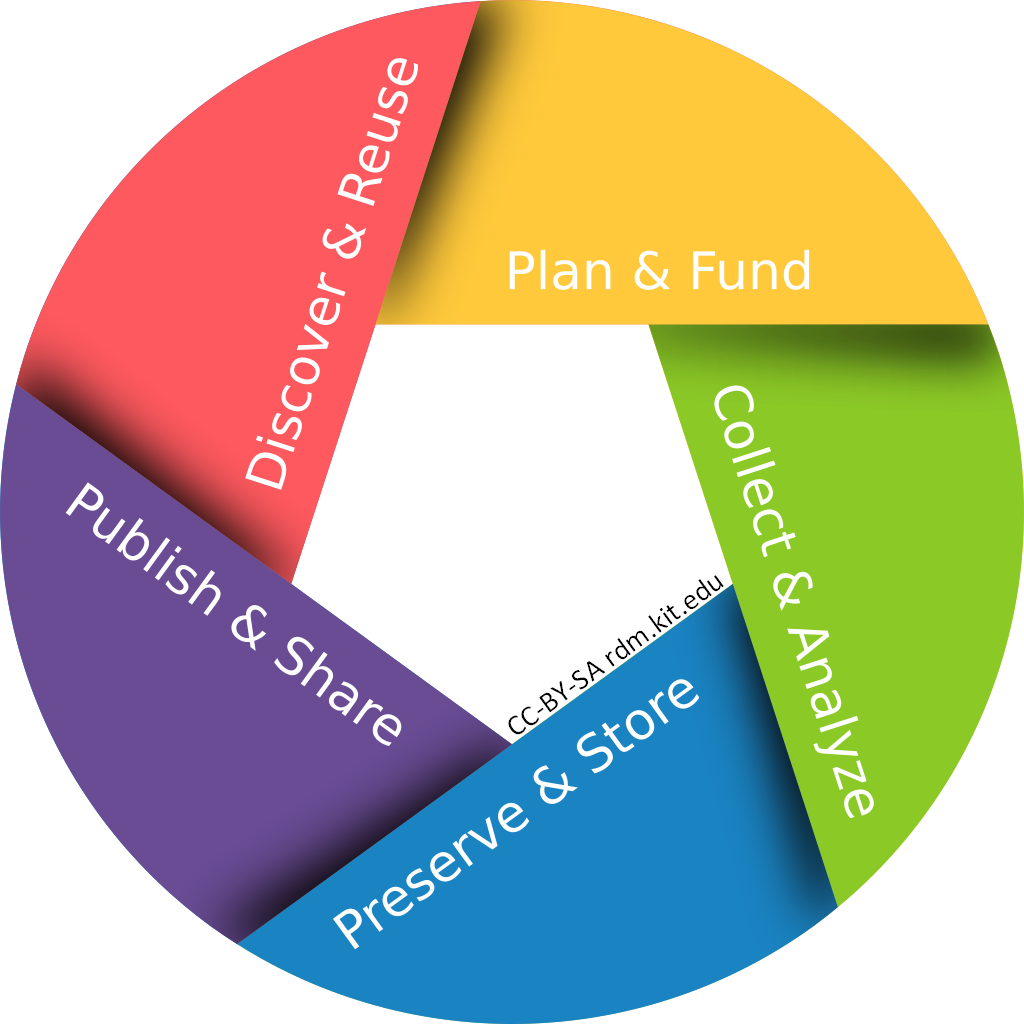
 Plan & Fund: Research data management begins with systematic planning: What data are needed, collected, processed and stored? Project funders usually require structured data management as early as the application stage. At the same time, funds for research data management can be applied for. For this purpose, so-called data management plans (DMPs) have become established in research data management. Tools such as RDMO and the DMPTool support the creation of DMPs for funders and project management.
Plan & Fund: Research data management begins with systematic planning: What data are needed, collected, processed and stored? Project funders usually require structured data management as early as the application stage. At the same time, funds for research data management can be applied for. For this purpose, so-called data management plans (DMPs) have become established in research data management. Tools such as RDMO and the DMPTool support the creation of DMPs for funders and project management.
 Collect & Analyze: The generation and collection of data, e.g. with sensors or simulations on high-performance computers, is essentially the responsibility of the researchers, as is the analysis, e.g. by algorithms & software. In this process, it is also important to collect the necessary metadata to describe the research data, this includes scientific, administrative, as well as information technology metadata. A tool that supports researchers in the collection and analysis is the electronic laboratory notebook (ELN).
Collect & Analyze: The generation and collection of data, e.g. with sensors or simulations on high-performance computers, is essentially the responsibility of the researchers, as is the analysis, e.g. by algorithms & software. In this process, it is also important to collect the necessary metadata to describe the research data, this includes scientific, administrative, as well as information technology metadata. A tool that supports researchers in the collection and analysis is the electronic laboratory notebook (ELN).
 Preserve & Store: Research data should be stored in an appropriate repository, ideally subject-specific or institutional repositories. If possible, research data should be stored together with good documentation to enable subsequent use, especially by third parties. An important criterion for the storage infrastructure is the possibility of long-term archiving, e.g. via tape storage.
Preserve & Store: Research data should be stored in an appropriate repository, ideally subject-specific or institutional repositories. If possible, research data should be stored together with good documentation to enable subsequent use, especially by third parties. An important criterion for the storage infrastructure is the possibility of long-term archiving, e.g. via tape storage.
 Publish & Share: Access conditions must be defined for the further use of the data, i.e. access and usage rights, which may also include the granting of patents and licenses. In order to uniquely identify and reference the files generated, it makes sense to assign persistent identifiers (PIDs). For the widest possible dissemination, existing networks and specialist communities should be integrated via an already existing and possibly certified infrastructure.
Publish & Share: Access conditions must be defined for the further use of the data, i.e. access and usage rights, which may also include the granting of patents and licenses. In order to uniquely identify and reference the files generated, it makes sense to assign persistent identifiers (PIDs). For the widest possible dissemination, existing networks and specialist communities should be integrated via an already existing and possibly certified infrastructure.
 Discover & Reuse: Good research data management enables other researchers to search for and reuse the results. These do not have to generate the data again at great expense, but can build on the current state of knowledge. To find data, there are both individual repositories and aggregating services such as re3data or DataCite. Here, too, researchers must observe the legal framework and good scientific practice.
Discover & Reuse: Good research data management enables other researchers to search for and reuse the results. These do not have to generate the data again at great expense, but can build on the current state of knowledge. To find data, there are both individual repositories and aggregating services such as re3data or DataCite. Here, too, researchers must observe the legal framework and good scientific practice.